Map este o structură de date cu ajutorul căreia putem asocia valori (mapped value) unor anumite chei (key value). Modul de operare al structurii de date Map este similar cu al unui vector de frecvență, însă, dacă în cazul unui vector de frecvență, valoarea cheie este reprezentată doar de tipul de dată int, la Map putem avea orice tip de date.
Într-un Map, valorile sunt ordonate în funcție de key value.
- Cum folosim Map?
Primul pas este includerea librăriei <map> în programul nostru:
#include <map>
Al doilea pas este inițializarea unui map:
map<key_data_type, value_data_type> m;
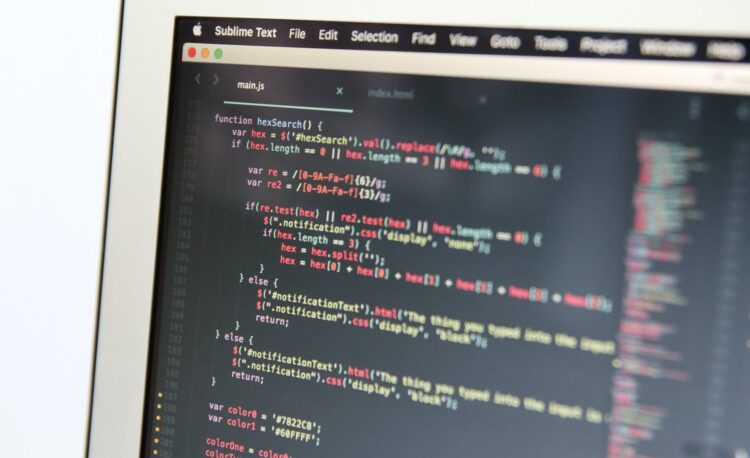
Pentru a vedea concret cum funcționează structura de date Map, voi lua ca exemplu problema #2268 de pe pbinfo.ro. În rezolvarea acesteia, vom folosi un Map. Numele elevilor vor reprezenta câte un key value, iar frecvența fiecărui nume un mapped value.
#include <iostream>
#include <map>
using namespace std;
int n;
string nume; // numele care vor fi citite
map <string, int> M; // map având key_value de tipul string(nume), și mapped_value de tipul int(frecvență)
map <string, int> :: iterator it; // cu ajutorul lui, vom itera prin map
pair <string, int> elev; // păstrez elevul cu frecvența maximă și primul în ordine alfabetică. elev.first va reprezenta numele elevului, iar elev.second frecvența acestuia
int main(){
cin >> n;
for(int i = 1; i <= n; i++){
cin >> nume; // citesc n nume
M[nume]++; // măresc frecvența numelui
}
for(it = M.begin(); it != M.end(); it++){
// aici, it -> first va reprezenta fiecare nume din map, iar it -> second frecvența acestuia
if(elev.second < it -> second){
// dacă întălnesc un nume cu frecvență mai mare, îl păstrez
elev.first = it -> first;
elev.second = it -> second;
}else if(elev.second == it -> second && elev.first > it -> first){
// dacă întălnesc un nume cu aceeași frecvență, dar care este mai mic lexicografic(adică, este plasat înaintea lui elev.first în ordinea alfabetică) decât ceea ce am deja în variabila elev, îl păstrez
elev.first = it -> first;
elev.second = it -> second;
}
}
cout << elev.first << " " << elev.second; // afișez elevul cu frecvența maximă și care este primul în ordine alfabetică
return 0;
}În mod asemănător, se rezolvă și problema #2217.
Întrucât mai sus am specificat structura de date unordered_map, vă voi prezenta diferențele dintre aceste 2 structuri de date și când trebuie să le folosim.
Vom folosi Map atunci când avem nevoie de date/informații în ordine! Altfel, dacă ordinea elementelor nu este necesară, este mai bine să folosim unordered_map!
Pentru a folosi unordered_map, avem nevoie de librăria <unordered_map> :
#include <unordered_map>
Diferențele majore dintre cele 2 structuri de date sunt:
- Ordonarea: Map ne asigură că elementele vor fi mereu în ordine, în schimb, Unordered Map nu ne permite acest lucru (de aici și numele)
- Eficiența
Map:
- inserare: log(n) + rebalance
- ștergere: log(n) + rebalance
- căutare: log(n)
- implementare: Self Balancing BST (de exemplu: Red-Black Tree)
Unordered Map:
- inserare: O(1) în medie sau O(n), în cel mai rău caz
- ștergere: O(1) în medie sau O(n), în cel mai rău caz
- căutare: O(1) sau O(n)
- implementare: Hash Table
Problema #3626 este tipul de problemă în care nu avem nevoie de ordinea elementelor, ci trebuie doar să știm dacă un element există sau nu. Știm:
v[i] + v[i + 1] + ... + v[j] = v[1] + v[2] + ... + v[j] - (v[1] + v[2] + ... + v[i - 1]), deci s(i, j) = sp[j] - sp[i - 1], i <= j, sp[] = vector de sume parțiale
Prin urmare, vom construi sumele parțiale și vom stoca fiecare sumă de la 1 la i și indicele la care se obține aceasta într-un unordered_map. Pasul următor ar fi să verificăm la fiecare pas dacă suma X – s a mai fost obținută, iar dacă acest lucru se întâmplă, vom actualiza lungimea minimă, făcând diferența dintre indici.
#include <iostream>
#include <unordered_map>
using namespace std;
int n, s, x, mini = int(1e9), sp; // (1e9) <=> 10^9 = 1.000.000.000
unordered_map <int, int> m; // unordered map unde key value = suma de la 1 la i, iar mapped value = indicele la care a fost obținută suma, adică i
int main(){
cin >> n >> s;
for(int i = 1; i <= n; i++){
cin >> x;
sp += x; // adaug la sumă
m[sp] = i; // sumei de la 1 la i, sp, îi corespunde indicele i
if(m[sp - s]) // dacă mai obținut suma sp - s => există o secvență de lungime i - m[sp - s] cu suma s, acest lucru fiind echivalent cu: "suma de la indicele mp[sp - s] + 1 și până la i este egală cu s".
mini = min(mini, i - m[sp - s]); // actualizez rezultatul
}
if(mini == int(1e9))
cout << "nu exista";
else cout << mini;
}
Colegiul Național “B. P. Hasdeu”, Buzău